Как обеспечить мгновенный доступ к файлам
Среди преимуществ хранилищ данных на базе программно-конфигурируемых сетей особое место занимает их высокая производительность. Благодаря виртуализации каждый файл может быть доступен мгновенно, как если бы он находился на локальном диске, хотя реально он может быть размещен на удаленном сервере в любой точке планеты – лишь бы туда был высокоскоростной доступ.
Рост объемов данных, постоянная потребность в получении дополнительной информации, которой может не быть в локальном доступе, вынуждают разработчиков решений искать способы мгновенной доставки данных потребителю. Решения класса SDS построены на принципах, обеспечивающих моментальный доступ к файлам в условиях обработки больших объемов информации.
Традиционно проблема роста объемов данных часто решается путем добавления все новых и новых сетевых устройств хранения данных (NAS-устройств, файлеров). Сами они относительно недороги и до определенного масштаба проблемы неплохо с ней справляются. Однако они медленнее, чем, например, решения, основанные на прямом подключении к серверу (DAS) или на сетях хранения данных (NAS) – все данные должны проходить через их процессоры. У них также ограничена масштабируемость внутренней памяти, и, когда объем новых данных превышает объем памяти файлера, это приводит к появлению «островков данных», которыми очень сложно управлять. Кроме того, хранение файлов с помощью большого числа NAS-устройств приводит к росту расходов на администрирование и управление данными.
Главное отличие SDS от хранилища, использующего традиционные протоколы передачи данных, состоит в том, что оно представляет потребителю удаленные устройства хранения как локальные, делая доступ к данным таким же быстрым. В основе решения лежит хорошо знакомая виртуализация, но есть и важная особенность, заключающаяся в том, что используются программно-определяемые сети (Software defined network, SDN).
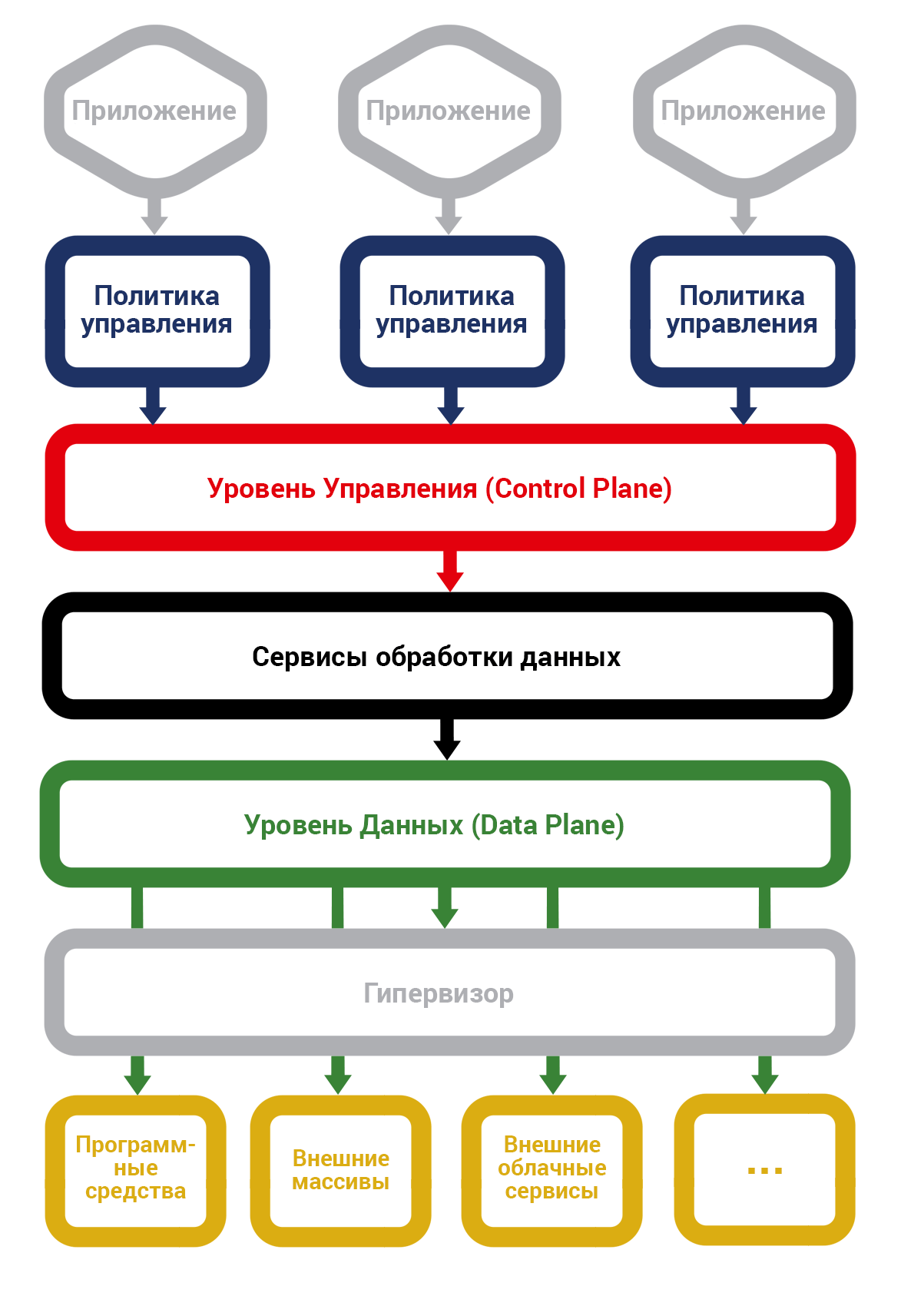
С инфраструктурной точки зрения производительность SDS достигается при помощи разделения системы на уровень данных и передающий команды устройствам уровень управления. Это также дает дополнительную функциональность системе.
Базовая концепция SDS-инфраструктуры
С аппаратной точки зрения смысл построения SDS, обеспечивающего мгновенный доступ к файлам, заключается в использовании самого производительного оборудования: SSD-дисков для хранения кэша данных, сетевого оборудования 10/100 Гбит и т.п. – всего самого высокоскоростного, емкого и с минимальным временем доступа.
SDS не предполагает протоколов для передачи данных по сети, а эмулирует устройства хранения. Все эти протоколы – FTP, NFS, SMB и др., как и работающие по ним сетевые устройства, – не позволяют дать мгновенный доступ к любому удаленному файлу. Сами устройства хранения данных физически могут располагаться где угодно – они презентуют данные в сеть посредством технических протоколов, например, FiberChannel или iSCSI, а потребитель присоединяет сгруппированные нужным образом устройства с помощью драйверов к своей системе как локальные диски.
Для ускорения работы с данными могут использоваться два физических уровня хранилища: на SSD для хранения часто используемой клиентом информации и на стандартных HDD для постоянного хранения данных. Таким образом «медленные» жесткие диски не становятся слабым звеном, тормозящим работу всей системы. Мы должны учитывать, что за последнее десятилетие быстродействие ЦПУ выросло в 8-10 раз, на порядок возросли скорости работы сетей и динамической оперативной памяти, в то время как производительность жестких дисков (HDD) увеличилась только в 1,2 раза. Это и вынуждает использовать дорогую, но быструю флэш-память (SSD).
Идея SDS еще очень молодая, но сегодня уже выпускается серийное оборудование с логикой хранения, абстрагированной в программном слое. Это также описывается как кластерная файловая система для конвергентного хранения. В качестве примеров систем с открытым исходным кодом назовем GlusterFS, Ceph, VMware Virtual SAN.
Зная, какими темпами растут объемы данных в компаниях, мы закономерно вынуждены решать задачи построения системы хранения, обеспечивающей неограниченное (или хотя бы очень большое, на порядки превышающее текущие пиковые потребности) эластическое масштабирование данных. И здесь нам на помощь также приходит SDS.
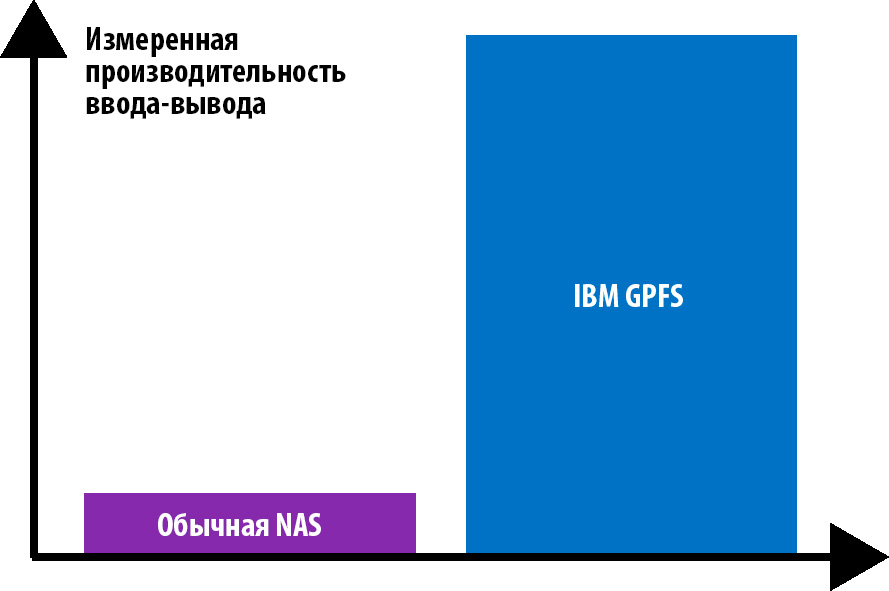
Программно-определяемое хранение данных позволяет выполнять горизонтальное масштабирование, сохраняя единую управляемую корпоративную систему, и при этом использовать относительно недорогие стандартные аппаратные средства. Например, разработанная IBM общая параллельная файловая система (GPFS) обеспечивает значительно большую производительность ввода/вывода после добавления аппаратных средств, по сравнению с обычной NAS.
Сравнение производительности ввода/вывода GFPS и NAS
Говоря о безграничной масштабируемости, мы имеем в виду следующие характеристики программно-определяемого хранения (на примере GPFS от IBM): максимальный размер файловой системы – 1 трлн терабайт, 263 файлов в одной файловой системе, поддержка IPv6, от 1 до 16 384 узлов в кластере. Что же касается производительности, то руководитель департамента систем хранения данных IBM Россия и СНГ Андрей Солуковцев СНГ называет такие цифры: «По сравнению с разрозненными системами хранения данных использование SDS позволяет увеличить производительность в 5–7 раз. Встроенные технологии компрессии способны обеспечить сжатие данных в 2 раза. И, конечно, в разы возрастает скорость ввода в эксплуатацию новых систем, ведь для установки новых элементов в SDS требуется всего около 40 минут».
В России уже оценили преимущества SDS. Так, Александр Герасимов, директор направления ИТ и облачных
ресурсов аналитического агентства J’son & Partners Consulting, говорит о перспективах для многих рынков: «Если распространить
подход «программно-определяемое все» на СХД и сети, появится возможность формировать полностью виртуальные контейнеры для любых приложений,
так называемые Software Defined Data-centers (SDDS), на базе объединенных в пулы дешевых серверов стандартной архитектуры.
Это, в свою очередь, позволит коммерческим провайдерам и внутренним ИТ-службам создавать виртуальные дата-центры для любых приложений,
включая «тяжелые» ERP-системы, биллинг, АБС и так далее, при этом чрезвычайно эффективно используя аппаратные ресурсы физических дата-центров».
А технический директор телекоммуникационной компании Caravan Дмитрий Канаев обращает внимание на стоимость
владения: «SDS не требует дорогих специализированных решений. А значит, пользователь будет избавлен от головной боли, связанной с прекращением их
поддержки производителем, оперативным поиском замены при поломке, необходимостью содержать высококвалифицированных инженеров. Обычно в
качестве узлов кластера в SDS используются x86 стандартной архитектуры, а они просты в эксплуатации и имеют много альтернатив».